
Effective Schema Design for SQLite
Structuring Your Database for Success

In our previous blog, we covered concurrency management in SQLite, discussing how it ensures data accuracy when multiple users interact with the database at the same time. Now, we turn to schema design, which is the next essential topic to master.

Schema Design involves organizing your database by creating tables, defining relationships, and reducing data duplication. For example, in a bookstore database, you'd have separate tables for books and authors that are linked together.
In this post, we’ll guide you through key concepts like normalization, indexing, and relationships between tables, providing practical examples to help you design a successful SQLite database.
Understanding Normalization
Normalization is the process of organizing data to minimize redundancy and improve data integrity. It involves splitting large tables into smaller ones and defining relationships between them.
Example: A Simple Bookstore Database
Let’s say you’re building a database for a bookstore. Initially, you might create a single table that looks like this:

In this table, information about authors is repeated, which is inefficient. Instead, we can normalize the data:
Create a separate table for authors:

Then, modify the books table to reference the author:

This approach eliminates redundancy and keeps your data organized.
Example 1: Student Enrollment System
Consider a student enrollment system for a university. If we create a single table for students and courses, it might look like this:

Here, both the course and instructor information are repeated. Normalizing this data involves creating separate tables for students, courses, and instructors:
Students Table:
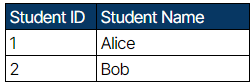
Courses Table:

Instructors Table:

Now, each piece of information is stored only once, making updates easier and maintaining data integrity.
Indexing for Faster Queries
Indexes are like a book's table of contents—they help you find information quickly. By creating indexes on frequently searched columns, you can significantly speed up data retrieval.
If you often search for books by author, you can create an index on the Author ID column:
Example: Indexing Author Names
CREATE INDEX idx_author ON books(AuthorID);This index will speed up queries that filter or sort by author, improving performance.
Example 2: Product Inventory System
If you frequently search by Product Name, you can create an index to optimize those queries:
Example: Indexing Product Names
CREATE INDEX idx_product_name ON products(ProductName);This index will speed up searches like:
Example: Querying Products by Name
SELECT * FROM products WHERE ProductName = 'Laptop';Establishing Relationships Between Tables
Defining relationships between tables helps maintain data integrity. In our bookstore example, we established a one-to-many relationship between authors and books. Each author can write multiple books, but each book has only one author.
Foreign Keys
You can represent this relationship in SQLite using foreign keys:
Example: Creating a Books Table with Foreign Key
CREATE TABLE books (
BookID INTEGER PRIMARY KEY,
Title TEXT,
AuthorID INTEGER,
Genre TEXT,
FOREIGN KEY (AuthorID) REFERENCES authors(AuthorID)
);This setup ensures that every book references a valid author, preventing orphan records.
Final Thoughts
Designing an effective schema in SQLite involves careful planning and consideration of how your data will be used. By normalizing your data, using indexing for faster queries, and establishing relationships between tables, you can create a robust database that supports your application’s needs.
With the right structure, your database will be efficient, scalable, and ready to handle whatever your application throws at it. For more insights on enhancing SQLite performance, check out our blog on Optimizing SQLite Performance.
Stay Updated! - Subscribe Now!
Want to master SQLite and enhance your database skills? Subscribe now to receive the latest insights, tips, and tutorials straight to your inbox! Join our community of learners and keep your data management skills sharp.